Jul 17, 2019 · post
New research: transfer learning for natural language processing
We discussed this research as part of our virtual event on Wednesday, July 24th; you can watch the replay here!
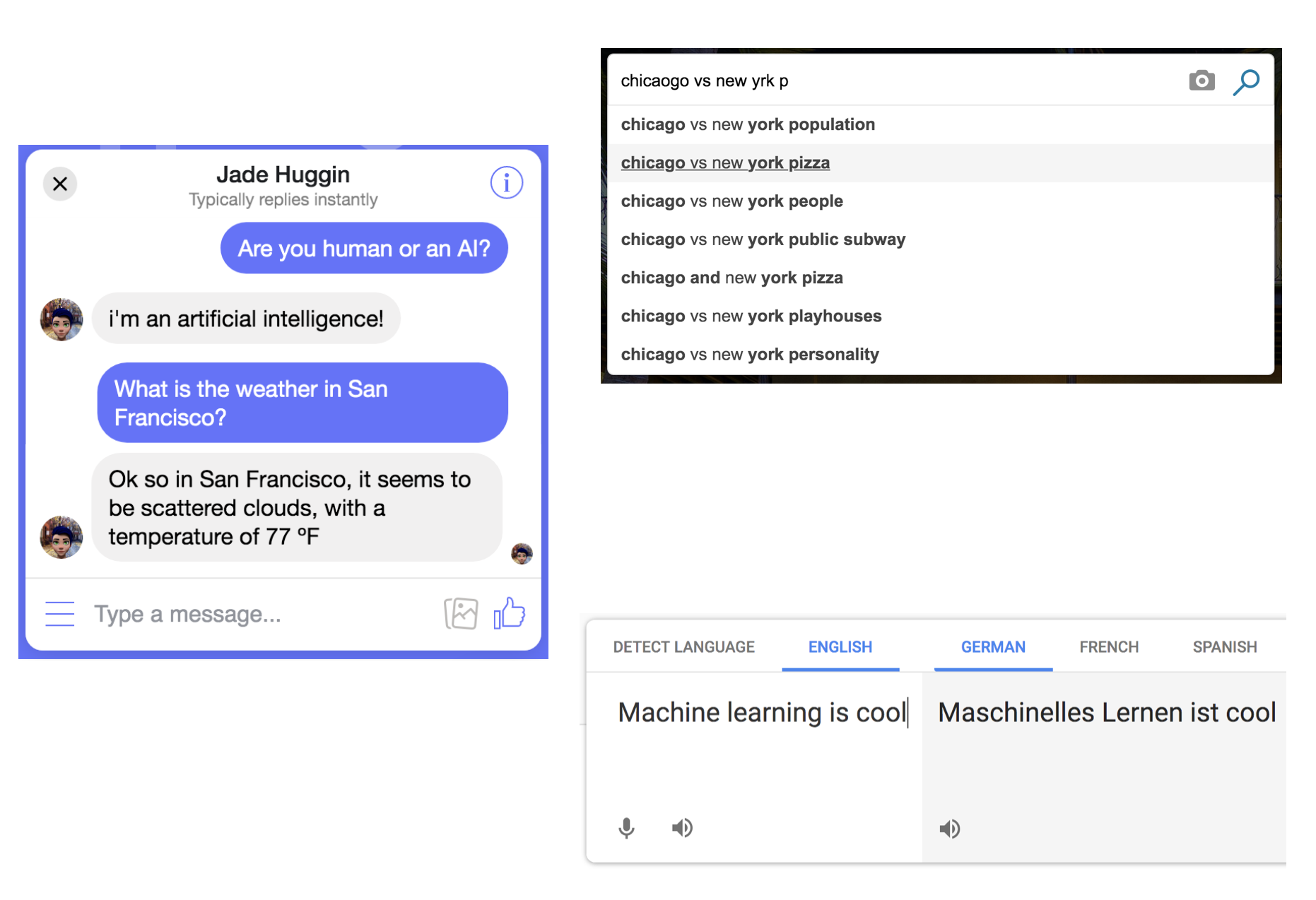
Machine learning powers systems that can translate language, guide searches, and interact with humans.
All around us we are seeing automated systems that are getting better and better at processing natural language. Machines that can work directly with natural language are powerful, especially as a human interface, because language is the most direct way in which we communicate. The potential impact of such systems is immense.
But systems that can do useful things with language must be intelligent - natural language is extremely complex, after all. Increasingly, machine learning algorithms are used to build this type of intelligence by allowing machines to automatically learn patterns of language.
Building machine learning systems ranges from extremely simple to extremely complex. Consider a system that identifies fraudulent credit card transactions.
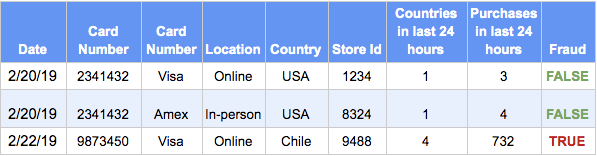
Many datasets can be represented neatly as a table. There are many useful statistical models that can find patterns in these datasets.
Teaching a machine to learn patterns of fraud is relatively simple. Given a large dataset of information about each transaction and a label indicating that the transaction was or was not fraudulent, there is no shortage of statistical methods that can identify patterns of fraud.
Natural language data is not so simple. It is, at its core, an ordered but idiosyncratic collection of symbols (characters, words, and punctuation). It can be long or short, and it could contain obscure references or slang. It is unstructured, and rarely meaningful in isolation. Meanings are often unstated, or only make sense in a larger context. Systems that process natural language must thus take these properties into account.
Much of the recent work in machine learning for NLP involves building sequence models that can take this sequential and contextual nature of language into account. With deep learning techniques we can build powerful sequence models that can automatically answer questions, translate between languages, detect emotion, and even generate human-like language.
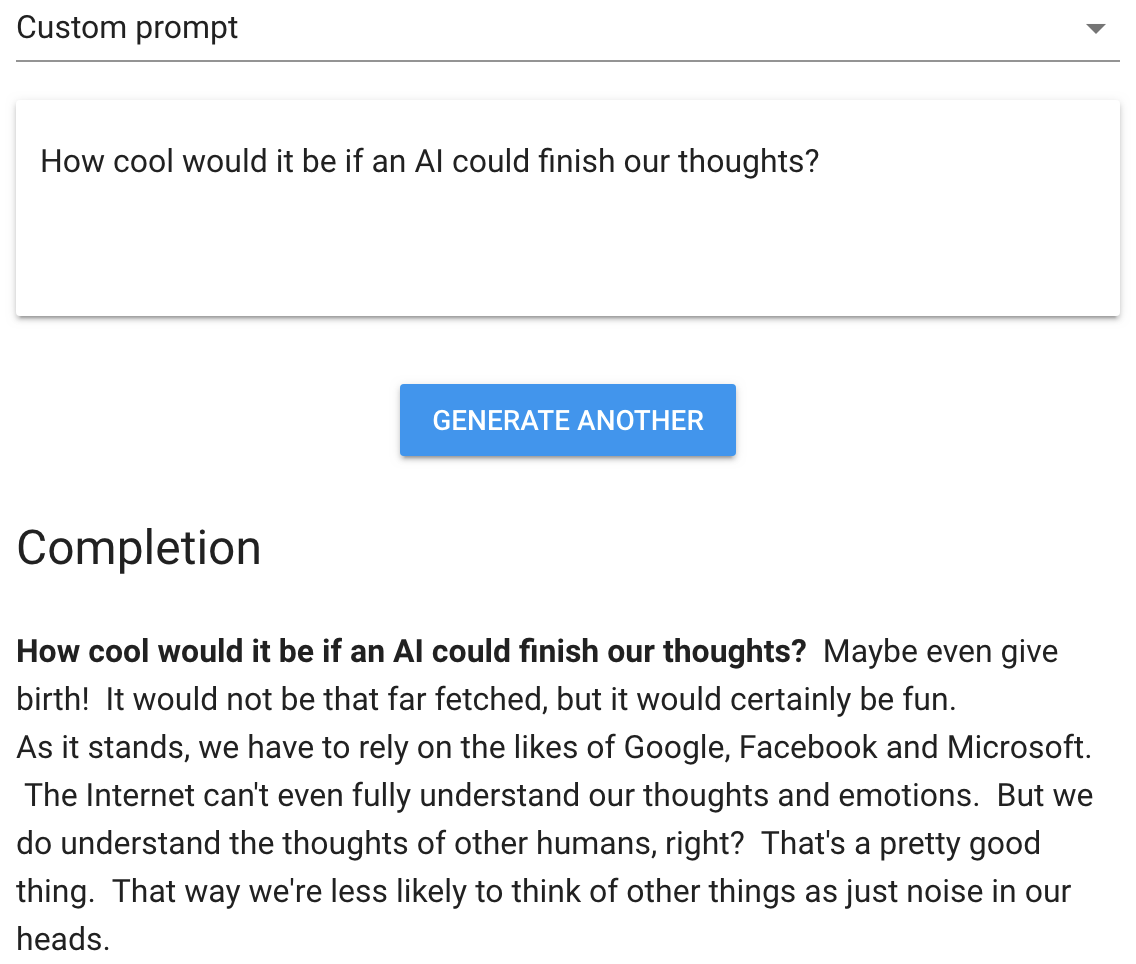
A cutting edge machine learning model can generate human-like text. From talktotransformer.com
Building these models, however, is expensive, complex, and requires massive datasets. The skills, budget, and data needed are out of reach for most organizations. These deep learning techniques, by themselves, often aren’t practical.
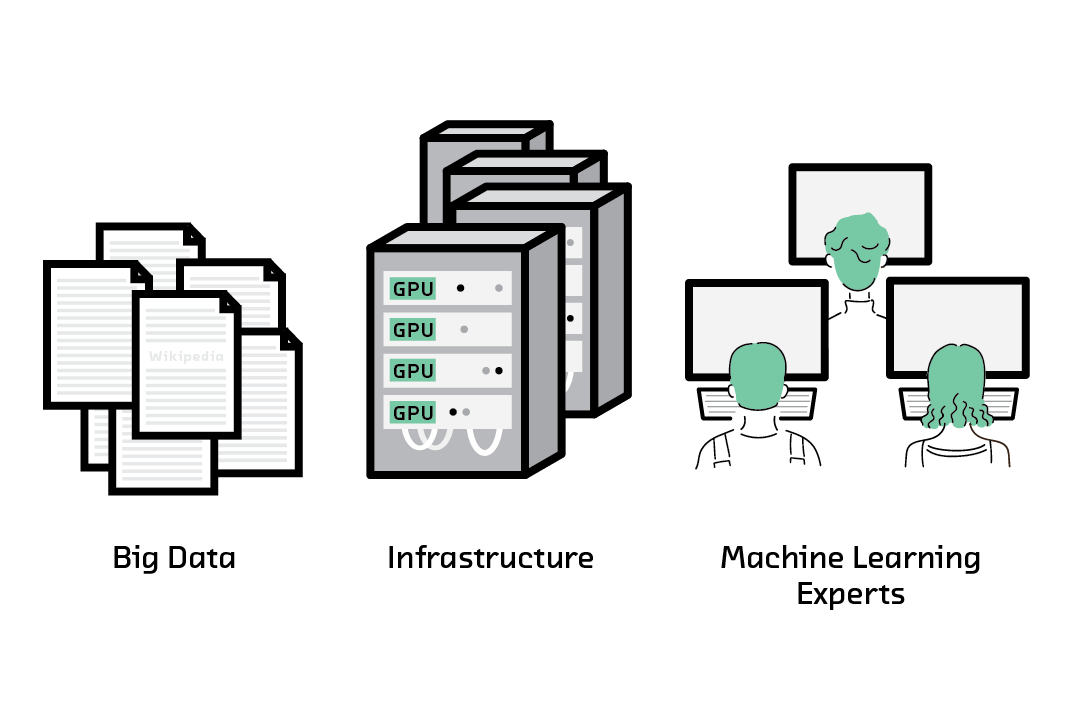
Transfer learning, a method for training models that incorporates knowledge re-use, solves these problems. Neither transfer learning nor sequence models are new technologies, but combining them provides new capabilities. With transfer learning for NLP, you no longer need the resources of a research lab or a Fortune 500 company to build cutting edge NLP products.
The latest report prototype from Cloudera Fast Forward Labs explores transfer learning for natural language processing and its implications. The prototype, which provides state-of-the-art sentiment analysis, was built with a small dataset of just 200 examples on an infrastructure budget of less than $25. With transfer learning, anyone can build state-of-the-art NLP systems without large datasets, trained experts, or expensive infrastructure.









