Jul 22, 2019 · featured post
New research: Deep Learning for Image Analysis
We discussed this research as part of our virtual event on Wednesday, July 24th; you can watch the replay here!
Convolutional Neural Networks (CNNs or ConvNets) excel at learning meaningful representations of features and concepts within images. These capabilities make CNNs extremely valuable for solving problems in the image analysis domain. We can automatically identify defects in manufactured items, reducing costs associated with quality assurance processes; we can now infer depth information and reconstruct 3D maps from 2D images without additional metadata, giving new potential to urban planning as well as entertainment experiences; we can perform pixel level separation of objects in images and video with applications ranging from public safety to medical robotics; and we can perform “super resolution” on photo images (upscale an image up to 10x) with a trained deep-learning system reconstructing, filling in, and thus sharpening images with information that would be omitted and lost using a standard digital zoom. It’s a long list.
Historically, CNN models have been manually designed (e.g Vgg16, ResNet50, InceptionV4 etc). While these models have demonstrated accuracy beyond human capabilities for many tasks, they tend to be large (parameters, floating point operations) and inefficient. More recently, approaches which enable the automatic discovery of model architectures (a field that is becoming known as neural architecture search or autoML) has shown promise for the discovery of high accuracy, high efficiency models. These autoML architectures, when applied to a broad range of tasks (e.g., object detection, segmentation, image generation et.c), are a recommended approach to unlock even more value for businesses.
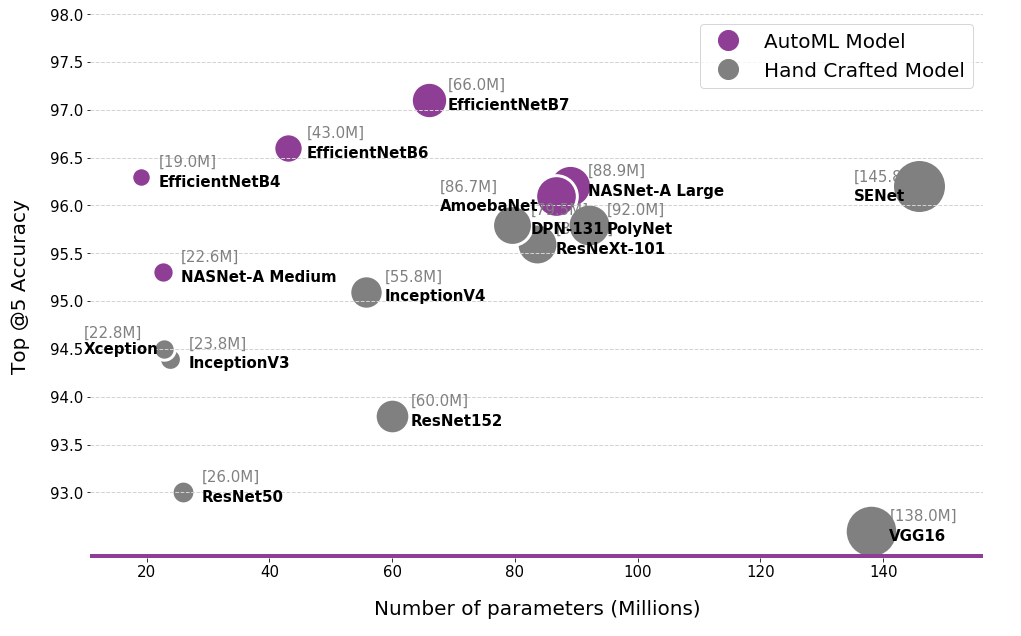
The landscape of competitive deep learning models for image analysis. We observe that neural architecture search (AutoML) has resulted in the discovery of highly accurate model architectures at a fraction of the costs (trainable parameters). These models are able to achieve more with less.
In our upcoming report, we cover a variety of practical considerations relevant to deploying deep learning models for image analysis. We begin by discussing a set of image analysis tasks and offer recommendations on which models to use and why. We also explore a set of approaches for interpreting models, tools/libraries, and ethical concerns that arise.
Prototype
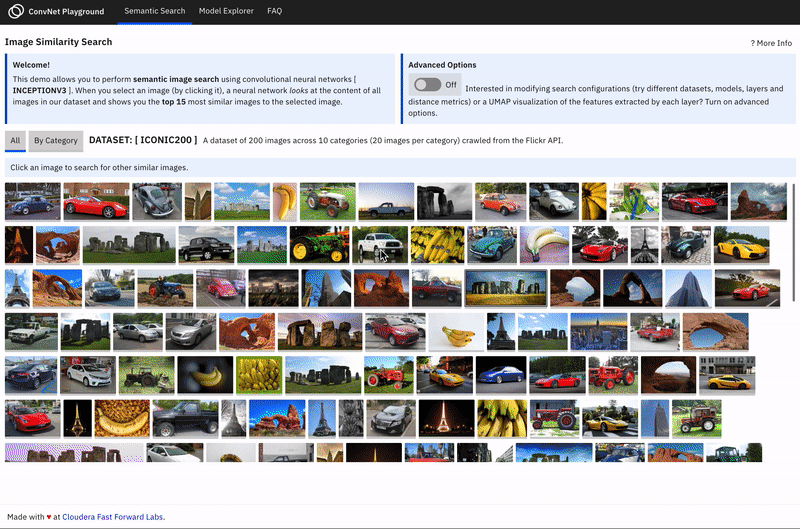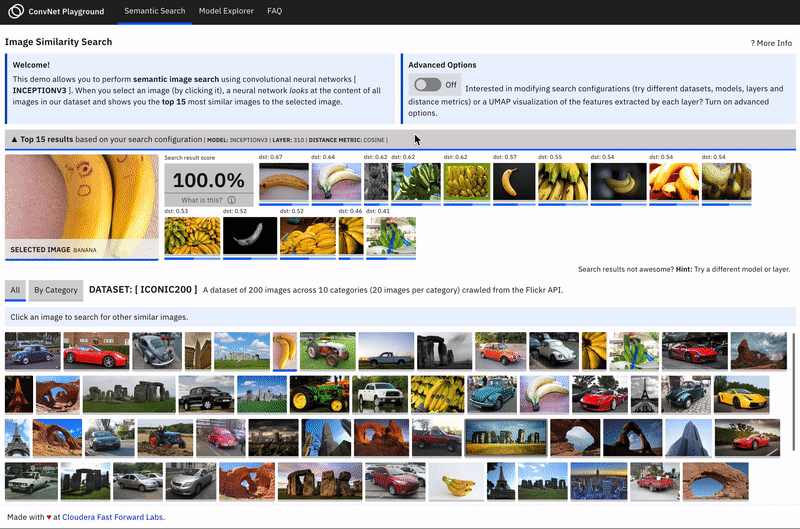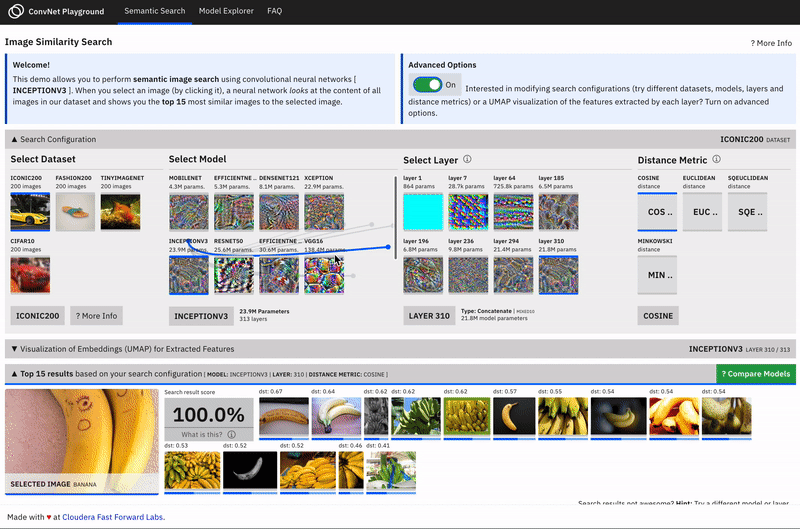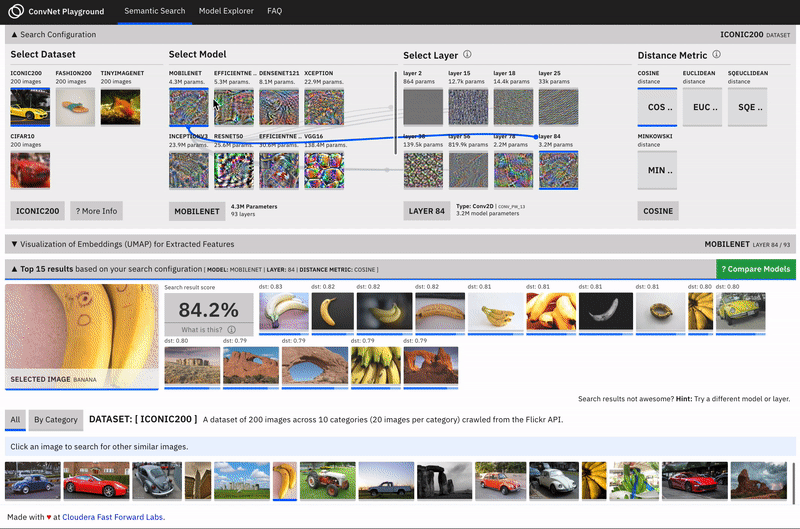
ConvNet Playground is an interactive visualization for exploring Convolutional Neural Networks applied to the task of semantic image search.
Along with this report, we have created a prototype - ConvNet Playground - an interactive visualization for exploring Convolutional Neural Networks, applied to the task of semantic image search. The prototype allows users to select search configurations (datasets, models, layers, distance metrics) and interactively explore how these impact search query performance. It allows users to ask questions such as: How does semantic search (with pretrained models) perform for given datasets? How well does each model/layer configuration capture “semantic meaning” for a given dataset? For a given search query, how does search performance compare for each model/layer configuration? What type of features/patterns are detected by various layers in a pretrained model?
The approach in this prototype is implemented in two stages (i.) we extract features from all images in our datasets using a pre-trained CNN (think VGG16, InceptionV3, etc. pre-trained on imageNet) (ii.) We compute similarity as a measure of the distance between these features.
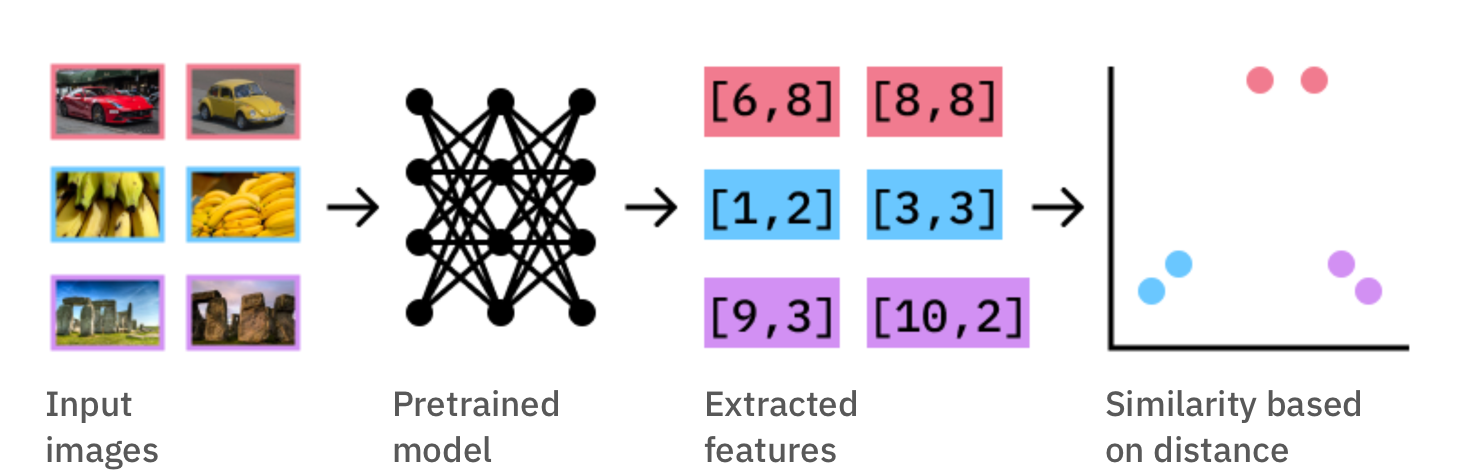
To implement semantic search, we start by extracting features from images in our dataset using pre-trained CNN models. Similarity is computed as the distance between these features.
Interested in a walkthrough of this prototype and learning more about other recent advances in deep learning for image analysis? We discussed this research as part of our virtual event on Wednesday, July 24th; you can watch the replay here!









