Sep 27, 2019 · newsletter
Other Orders: Re-contextualizing the Familiar
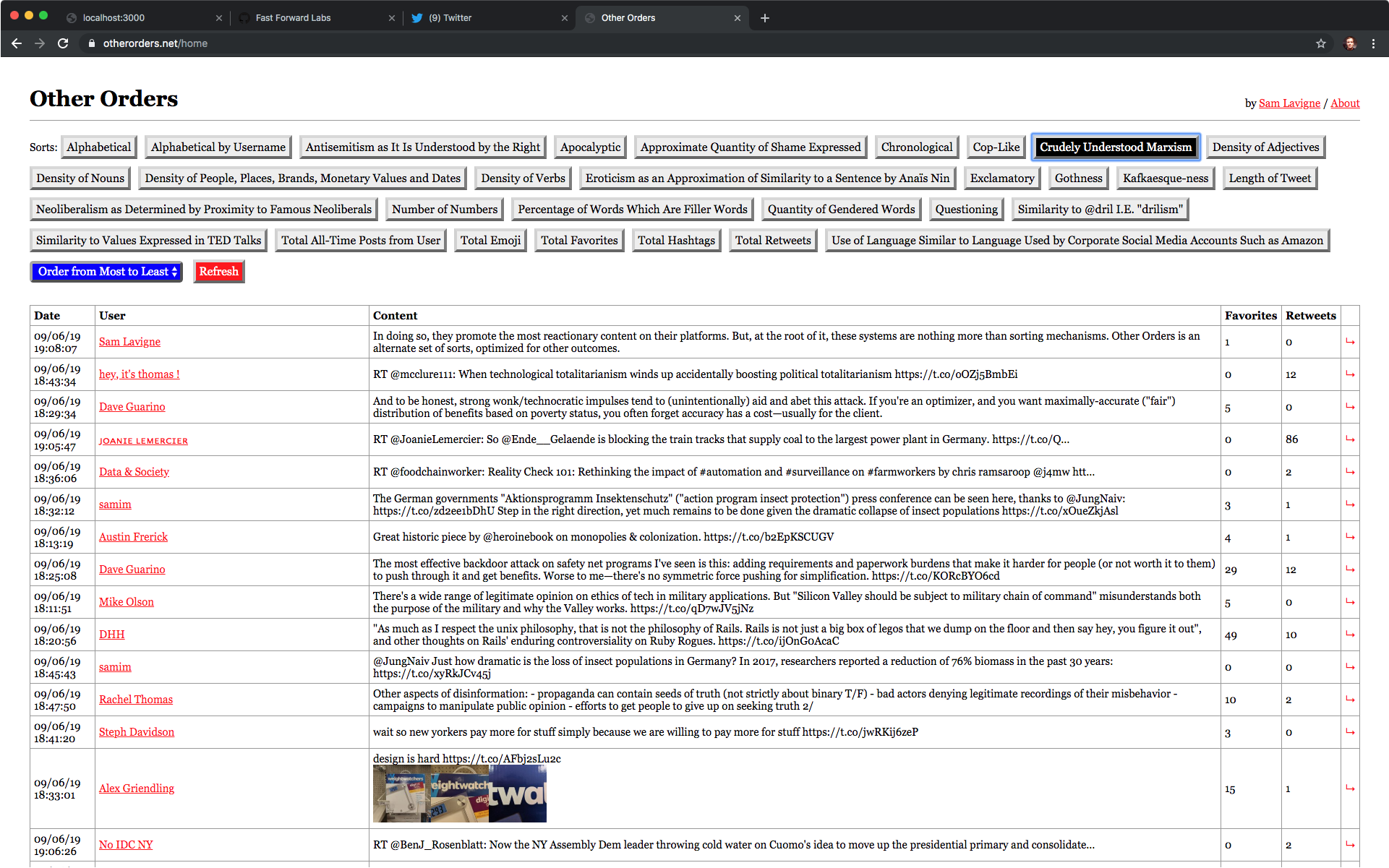
My Twitter feed sorted by semantic similarity to “crudely understood Marxism” using Other Orders.
To illustrate how categories shape our thoughts, the philosopher Michel Foucault cites Jorge Luis Borges’ (made-up) quotation from a “certain Chinese encyclopedia," where it is supposedly written that:
Animals are divided into: (a) belonging to the Emperor, (b) embalmed, (c) tame, (d) suckling pigs, (e) sirens, (f) fabulous, (g) stray dogs, (h) included in the present classification, (i) frenzied, (j) innumerable, (k) drawn with a very fine camelhair brush, (l) et cetera, (m) having just broken the water pitcher, (n) that from a long way off look like flies.
I thought of the Borges quote while reading through the list of Tweet sorting mechanisms in “Other Orders” - a project by Sam Lavigne:
Alphabetical; Alphabetical by Username; Antisemitism as It Is Understood by the Right; Apocalyptic; Approximate Quantity of Shame Expressed; Chronological; Cop-Like; Crudely Understood Marxism; Density of Adjectives; Density of Nouns; Density of People, Places, Brands, Monetary Values and Dates; Density of Verbs; Eroticism as an Approximation of Similarity to a Phrase by Anaïs Nin; Exclamatory; Gothness; Kafkaesque-ness; Length of Text; Neoliberalism as Determined by Proximity to Famous Neoliberals; Number of Numbers; Percentage of Words Which Are Filler Words; Quantity of Gendered Words; Questioning; Similarity to @dril; Similarity to Values Expressed in TED Talks; Total All-Time Posts from User; Total Emoji; Total Favorites; Total Hashtags; Total Retweets; Use of Language Similar to Language Used by Corporate Social Media Accounts Such as Amazon.
Both projects use alternate orders to make us think more critically about the ones we take for granted (the defaults). Lavigne wants to push back against recommendation systems that privilege engagement (views, likes, retweets, replies). Such systems can end up promoting content based on how controversial it is, regardless of its accuracy. Even the reverse-chronological sort, a default that feels ‘natural’ for our social media feeds, is a specific ordering choice with consequences. It means newness is privileged, and discourages making connections between Tweets across time.
On sorting
We sort by what is quantifiable. Engagement and chronology can be determined and sorted through metadata that is already numbers (add together views, likes and retweets for engagement; compare time for chronology). Part of the fun of the Other Orders list is how it moves between easily countable metadata, more advanced counting of types of words (nouns, verbs, numbers, emoji, filler words) and word similarity as calculated through word embeddings. It reminds me of building our prototypes, where you explore the options a new technology can open: “Ok, we can identify nouns; let’s see what it looks like if we sort by density of nouns… hmmm…. Ok, interesting. What else can we do?"
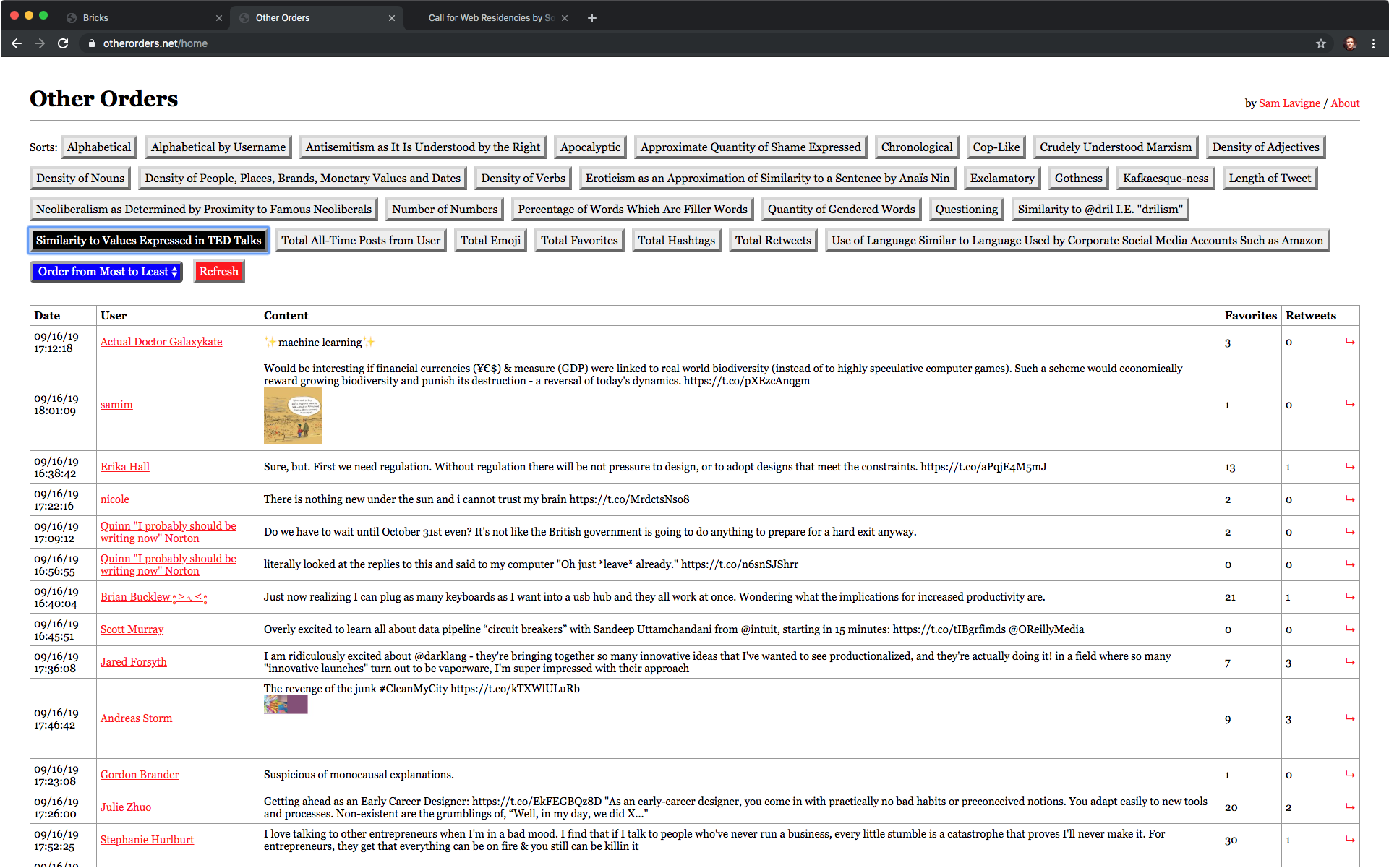
Sorting by “similarity to the values expressed in TED talks” got me a top tweet of “[sparkle emoji] machine learning [sparkle emoji]".
My favorite categories are the “similarity” ones, including: Similarity to Values Expressed in TED Talks, Similarity to @dril, and Kafkaesque-ness. All of these categories involve looking at similarity between the tweets and an example text using word embeddings. Each of these categories contains a recognizable style. One drawn from literature (Kafka), one from weird Twitter (@dril), and one from a particular genre of speaking (TED talks).
On the loss of context and making connections
One of the difficulties of fitting techniques like word embeddings into a product is the model’s lack of a sense of context. It can get you a similar sentence, but it may pluck that sentence out of a paragraph on a different topic. This makes using it for things like summarization a difficult (but not insurmountable) challenge (see our summarization prototype Brief). The cleverness of the similarity groupings in Other Orders is that they turn this lack of context to their advantage, sorting Tweets in a way that enables you to spot connections between people and topics that you would not otherwise have recognized. Looking at the top Kafka and @dril-like Tweets in my feed reminds me of looking at the rabbit-duck illusion: shift my head one direction and I can read the Tweet like a non-sequitur from @dril, shift it the other and I can figure out that in its original context it was a fragment from a larger thread.
Just knowing that Tweets could be sorted in these ways shifts my experience of regular Twitter. Having been exposed to the lens of “is this Tweet @dril-like?", I can start spotting @dril-like Tweets on my own. The @dril stuff is mostly for fun, but I can also see these alternate categories having a more substantial effect on how I understand my feed. Sorting by “Crudely Understood Marxism” (“Items are ordered relative to their semantic similarity to the phrase ‘workers must seize the means of production.'") in my feed shows mostly web developers, writers, and game developers (the main groups I follow) talking about structural frustrations with their work. I read and understood these Tweets before, but since seeing the pattern exposed through the ordering, I now recognize them as part of a larger thread. “Oh, there’s another Tweet about burnout or the need to unionize," I now think to myself, connecting it to that new category in my head.
Try it out
I recommend trying Other Orders for yourself. If you don’t have Twitter or don’t want to connect yours, play with sorting the sentences of works of literature on the about page; it will give you a good feel for how these sorting mechanisms can re-contextualize the familiar.









