Feb 5, 2020 · featured post
Deep Learning for Anomaly Detection
The full Deep Learning for Anomaly Detection report is now available.
You can also catch a replay of the webinar we reference below on demand here.
In recent years, we have seen an unprecedented increase in the availability of data in a variety of domains: manufacturing, health care, finance, IT, and others. Applications leverage this data to make informed decisions. This comes with its own set of challenges (and opportunities) when things start to fail; for instance, what happens when a piece of equipment fails or a network suffers from a security vulnerability? Companies may lose customers, or fixing things could take a while (which in turn adds to the costs). In short, everything from the organization’s bottom line to its reputation are at stake.
But what if we had the ability to reliably detect or identify when something goes wrong? This is the premise of anomaly detection, and the subject of our latest report.
Given the importance of the anomaly detection task, multiple approaches have been proposed and rigorously studied over the last few decades. The underlying strategy for most approaches to anomaly detection is to first model normal behavior, and then exploit this knowledge in identifying deviations (anomalies). This approach typically falls under the semi-supervised category and is accomplished across two steps in the anomaly detection loop.
The first step, which we can refer to as the training step, involves building a model of normal behavior using available data. Depending on the specific anomaly detection method, this training data may contain both normal and abnormal data points or only normal data points. Based on this model, an anomaly score is then assigned to each data point that represents a measure of deviation from normal behavior.
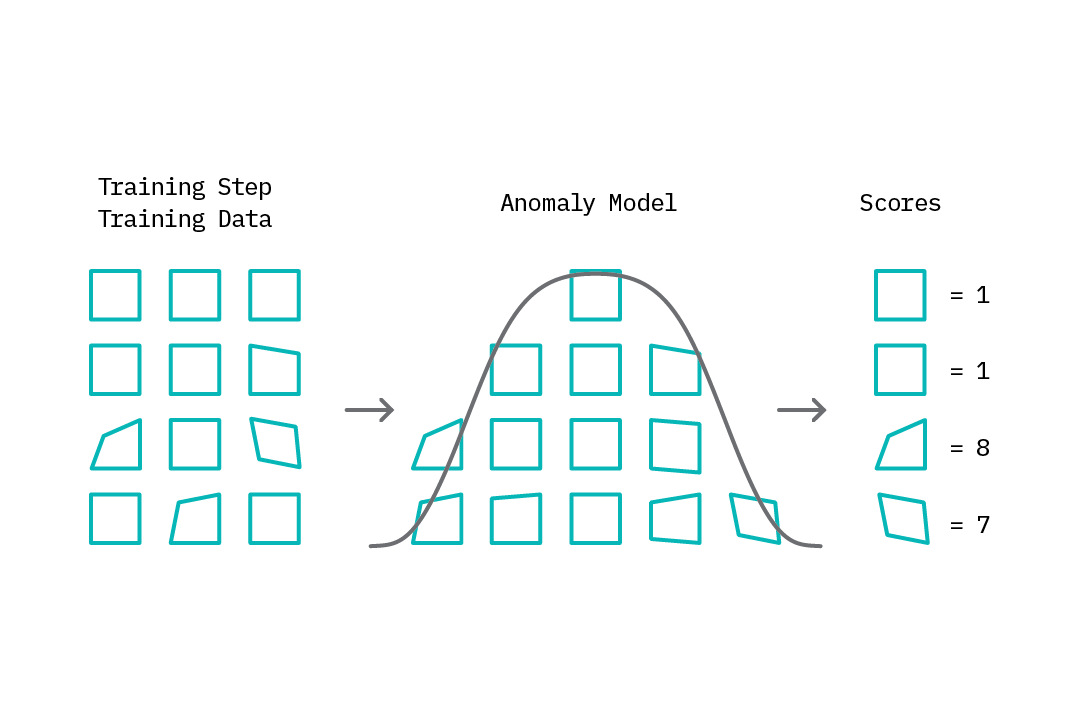
Figure 1: Training - Modeling normal behavior
The second step in the anomaly detection loop - the test step - introduces the concept of threshold-based anomaly tagging. Given the range of scores assigned by the model, we can select a threshold rule that drives the anomaly tagging process - e.g., scores above a given threshold are tagged as anomalies, while those below it are tagged as normal.
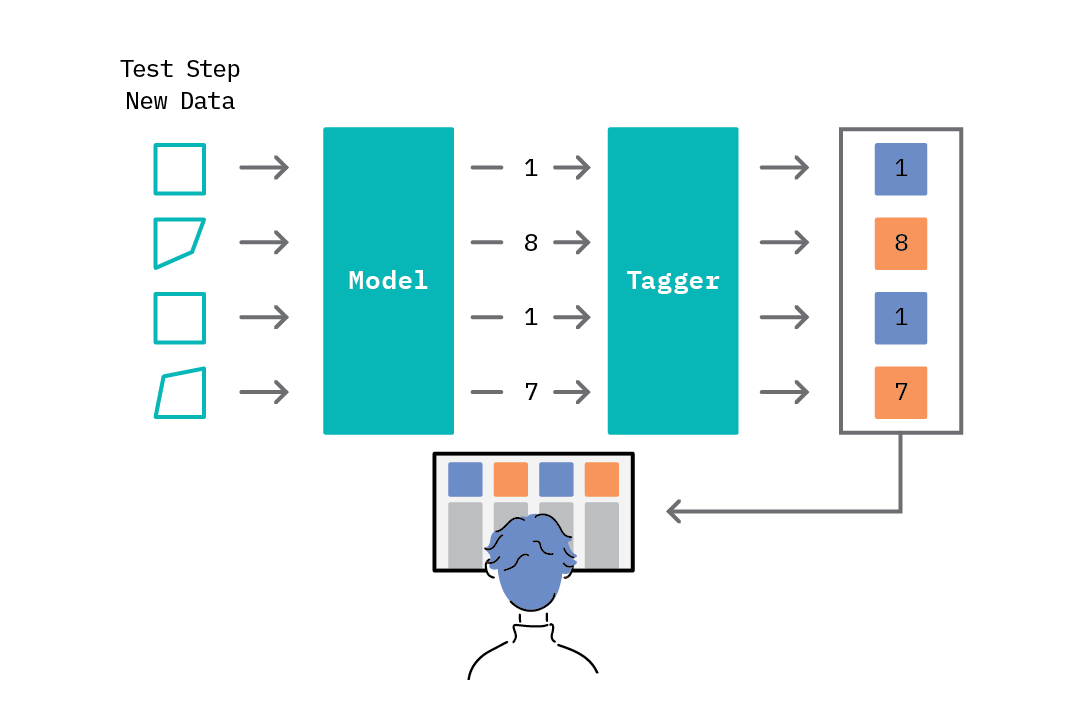 Figure 2: Testing - Threshold-based anomaly detection
Figure 2: Testing - Threshold-based anomaly detection
As data becomes high dimensional, it is increasingly challenging to effectively teach a model to recognize normal behavior. This is where deep learning approaches step in. The approaches discussed in our upcoming report typically fall under the encoder-decoder family, where an encoder learns to generate an internal representation of the input data, and a decoder attempts to reconstruct the original input based on this internal representation. While the exact techniques for encoding and decoding vary across models, the overall benefit they offer is the ability to learn the distribution of normal input data and construct a measure of anomaly respectively.
The forthcoming report and prototype from Cloudera Fast Forward Labs explores various such deep learning approaches and their implications. While deep learning approaches can yield remarkable results on complex and high dimensional data, there are several factors that influence the choice of approach when building an anomaly detection application. In our report we survey various approaches, highlight their pros and cons, and discuss resources and recommendations for setting up anomaly detection in a production environment, as well as technical and ethical considerations.
Want to learn more? Join us on Thursday, February 13th at 10:00am PST (1:00pm EST) for a live webinar on “Deep Learning for Anomaly Detection.” Nisha Muktewar and Victor Dibia of Cloudera Fast Forward Labs will be joined by Meir Toledano, Algorithms Engineer at Anodot.









