Jan 29, 2020 · post
A Symbiotic Relationship: Knowledge Graphs & Machine Learning
For the past decade, humans have unknowingly come to depend on Knowledge Graphs on a daily basis. From personalized shopping recommendations to intelligent assistants and user-friendly search results, many of these accepted (and expected) features have come to fruition through the exploitation of knowledge graphs. Despite their longstanding conceptual and practical existence, knowledge graphs were just added to the Gartner Hype Cycle for Emerging Technologies in 2018 and have continued to garner attention as an area of active research and development for their distinct ability to represent real-world relationships.
In this article, we’ll take a high-level look at what knowledge graphs are and explore a few ways they interact with the field of machine learning.
What is a knowledge graph?
With all the hype comes confusion. In its simplest form, a knowledge graph is a set of data points linked by relations that describe a real-world domain. A cursory Google search will result in a myriad of explanations, but I believe there are a few core concepts that characterize a knowledge graph implementation.
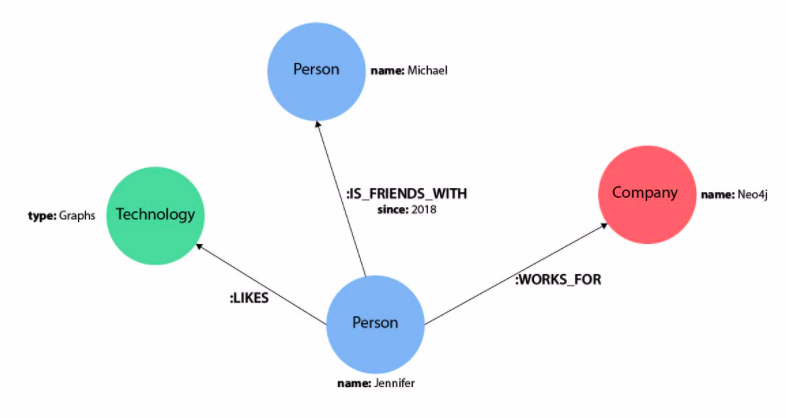
Image Credit
- It’s a graph - Contrary to traditional data stores, knowledge graphs are composed not only of entities, but also connections between each entity. In a graph network, these entities are called Nodes or Vertices and are connected together via Edges or Links. Graph data structures excel at modeling one-to-many relationships.
- It provides context - Knowledge graphs glean semantic meaning by design - namely, the meaning of the data is implicitly encoded in the data representation itself, making it easy to query and explore. In the example above, we can quickly interpret that Jennifer is a Person who works for a Company called Neo4j because of the inherent directional metadata structure.
- It’s intelligent - Knowledge graphs are built from dynamic, logical constructs - ontologies - that by default possess a framework supportive of inference. Regardless of the specific entities in the graph, the entity-to-entity connections hold fundamental meaning.
A Familiar Example
A concrete and relatable application of knowledge graph technology is demonstrated by Google’s Knowledge Graph which was launched in 2012 and has become a relied upon feature for all Google search users.
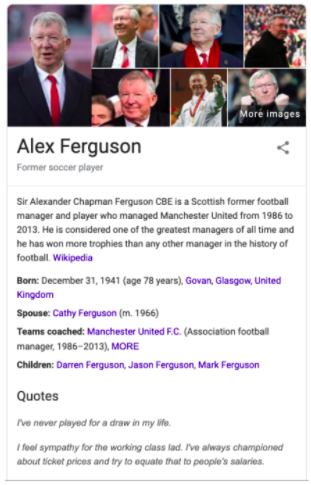
When searching for a specific person, Google provides users a side panel that contains relevant information surrounding the entity/subject in the query. This quick insight is made possible by Google’s Knowledge Graph - a pre-populated knowledge base of connected facts relating people, places, and things. Because the graph structure effectively represents this type of data by design, the facts seen above can be easily called upon to provide contextual insight.
Intersection of Machine Learning and Knowledge Graphs
Now that we have established a baseline intuition of what knowledge graphs are, let’s take a look at ways machine learning and knowledge graphs support each other.
Getting knowledge into a knowledge graph
Because knowledge graphs preserve relational information (and are therefore more complex than traditional data representations), the data they take in demands a more refined state. Specifically, the edges between nodes must be established and then wrangled into a complementary form before populating a graph.
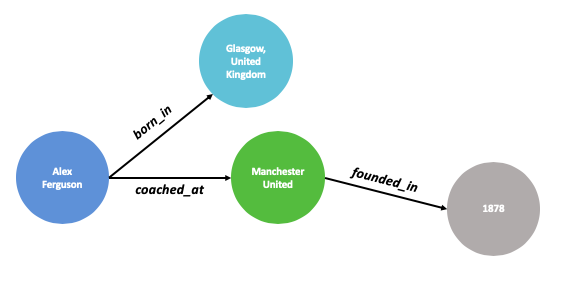
Let’s imagine a hand-crafted graph describing characteristics of Sir Alex Ferguson as seen above. Defining these entities and relationships is a simple endeavor for anyone knowledgeable of the English Premier League (EPL) and organizing the connections upfront allows the graph to be efficiently queried later on. But what happens if we want to create subgraphs for every manager in the EPL? Or every soccer manager in the world? Or every professional sports manager that ever existed?
Manually identifying all of these relationships by hand is not scalable. This is where machine learning and Natural Language Processing (NLP) offer intelligent solutions to automatically curate raw data into useable facts. The general techniques involved include sentence segmentation, part of speech tagging, dependency parsing, word sense disambiguation, entity extraction, entity resolution, and entity linking applied to corpuses of both structured and unstructured data.

The simplified example above is intended to highlight the general NLP process on a single sentence. In practice, organizations use more advanced, patented systems built on these underlying techniques to automatically extract information, resolve conflicting entities, and populate millions of entities into production knowledge graphs.
Getting richer knowledge out of a knowledge graph
“Increasingly we’re learning that you can make better predictions about people by getting all the information from their friends and their friends’ friends than you can from the information you have about the person themselves."
- James Fowler, Connected
The quote above poses a justified, but unconventional approach to predictive modeling. Traditional machine learning focuses on modeling tabular data that inherently cannot represent all of the cascading relationships found within networks and knowledge graphs. This often means data scientists are left trying to abstract, simplify, and even leave out predictive relationships baked into a knowledge graph’s structure. But what if features of every node in a knowledge graph could be derived from the context of all the nodes and edges around them?
There are few different methods for making use of connected features in machine learning, but a main area of attention is Knowledge Graph Embeddings (KGE). The goal of KGE’s is to learn a fixed vector space representation of any given node in a graph based on its nearby connections. Drawing a quick parallel to the Word2Vec algorithm (and concept of word embeddings) - where we learn a fixed vector representation for every word in a corpus based on nearby words - helps to frame the concept of KGEs. Specifically, the Node2Vec model expands upon ideas from Word2Vec by first randomly traversing subgraphs for each node in a network to build a large number of sequences [sentences]. Once we have a body of graph sequences [corpus], we can utilize Word2Vec methodology as it applies to text sequences to produce graph node embeddings.
Ultimately by learning embedding representations from the full context of a knowledge graph, we can extract deeply rich features to be used in downstream tasks. A few uses are:
- Link prediction - Can we find nodes that are likely connected or are about to be connected? (For example, a graph of products and customers connected by orders could be used to predict (and thus recommend) which new products should likely be connected to which new customers.)
- Supervised modeling - Embeddings can be fed as input features to supervised models for classification tasks.
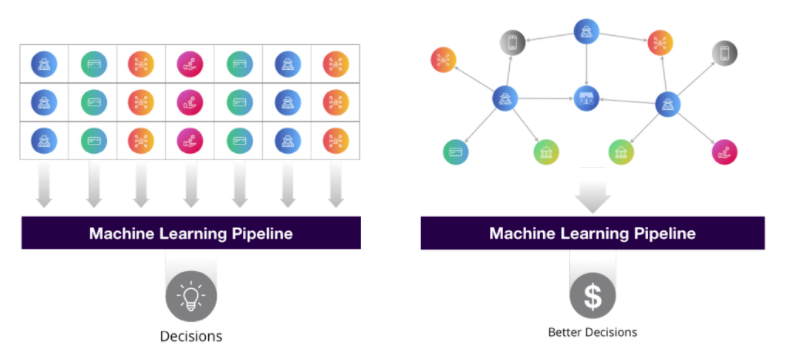
Image Credit
Final Thoughts
Knowledge graphs are an effective tool for modeling interconnected, real-world scenarios while retaining contextual details that are not easily captured with traditional data structures. In this article, we explored two examples that demonstrate the symbiotic relationship between knowledge graphs and machine learning, which only scratches the surface of the intersection between the two technologies. Additional concepts - like Graph Neural Networks and ML driven Entity Resolution - stand as exciting areas of research and application.










{kind=link}