Dec 24, 2019 · newsletter
Squote - semantic quote search
Here in the (virtual) Fast Forward lab, we’re currently deep in the topic selection process for FF13. While one or two of our research engineers take the lead for each report, we work through several rounds of discussion and debate about the merits and demerits of topics on our collective radar as a team. Part of that process is dreaming up potential prototype applications.
Our multi-talented designer/dev Grant proposed a prototype: given a block of text, find a relevant quote.
It tickled my brain in the right way, and I decided to try and build it. When doing speculative work, there is some wisdom in trying to fail fast, and - thanks entirely to the hard work of other people - I had something working a few hours later. So continuing a theme of “staying up late hacking with pre-trained models,” we offer you squote.xyz , a semantic search tool for quotes.
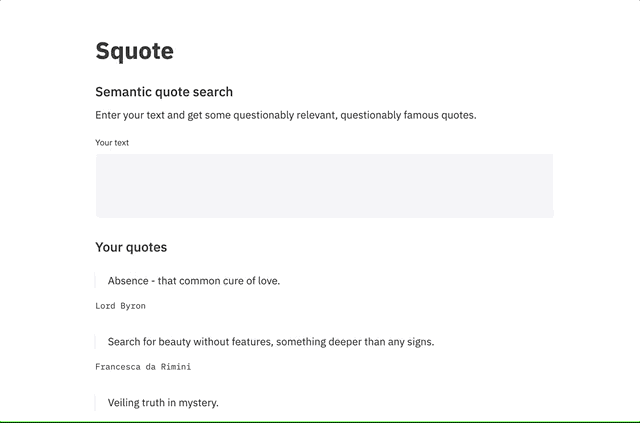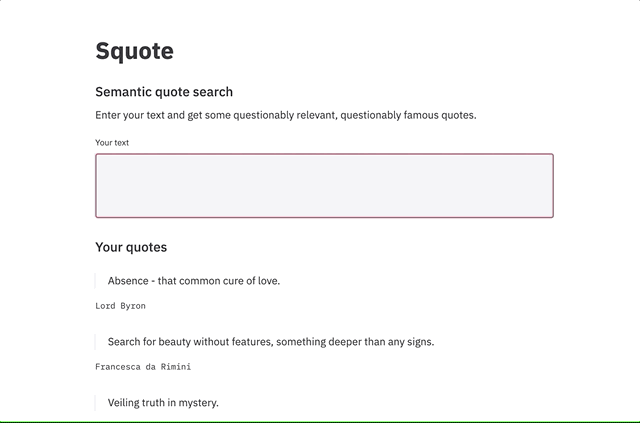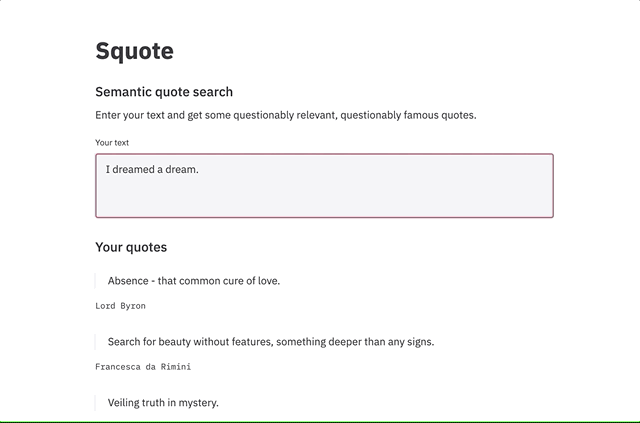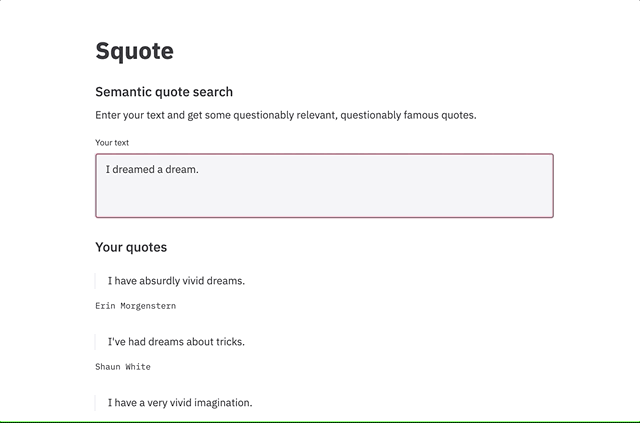
The premise is that given a block of text - say the body of an email, or a paragraph from an essay - Squote should return you a semantically related quote. By “semantically related” I mean “has a similar embedding under BERT, measured with cosine similarity.” The result is that entering some text about mountains might also return you some text about hills. However, entering a short specific phrase will not necessarily return a block of text containing that phrase: we compare whole text embedding of the input to the whole text embedding of the quote (the whole text embedding being taken here as the mean of the contextual word embeddings). As such, the presence of other words in the quote may reduce its similarity to a phrase it contains.
Useful search is complex and hard, and Squote is intended only as a minimally viable demonstration. Conveniently for the sake of this story, on precisely the same day I put together Squote, Google announced the use of BERT in their search engine in the blog post Understanding searches better than ever before. Not having had quite the same development investment as Google’s search engine, Squote certainly doesn’t always produce a quote that is obviously relevant. At the least though, it’s usually entertaining to ponder why it returned what it did. We hope you have some fun with it.
For those interested, the source is available for your perusal, use, and modification at cjwallace/squote. Squote is built entirely in python (including the interface) on three open source projects. Essentially all the functionality was provided “out-the-box” by these projects.
- BERT-as-a-Service is exactly what it sounds like! This repo allows you to host the BERT model as a micro-service, and provides a python client that can communicate with the service through a simple API. This reduces getting a state-of-the-art sentence embedding (a length 768 vector) to a simple function call in your python app.
- FAISS is a library for similarity search and clustering of vector representations. While it’s easy enough to define L2 or cosine similarity in pure python, when matching against embedding vectors representing a corpus of 75,000 quotes, it’s nice to know that someone else has thought about indexing that efficiently. After two native library installs, usage was incredibly straightforward through the python library (thanks to a prebuilt version at faiss_prebuilt).
- Streamlit is a new library for building interactive machine learning tools with python. It’s spiritually somewhere between RShiny and ObservableHQ, staying in pure python but incorporating a kind of reactive flow - when an input is updated, the output is regenerated without any explicit code to trigger it. It only took a few minutes to feel comfortable with the basic model of Streamlit, and I’ll definitely be keeping it in my toolbox.
The pace of advancement in natural language technology has increased substantially over the past 18 months, and seems impossible to keep up. However, I believe there are hundreds of useful natural language applications that could be built with what is rapidly becoming commodity technology (and maybe some fine tuning)! Happy building!









