Apr 1, 2020 · newsletter
Enterprise Grade ML
At Cloudera Fast Forward, one of the mechanisms we use to tightly couple machine learning research with application is through application development projects for both internal and external clients. The problems we tackle in these projects are wide ranging and cut across various industries; the end goal is a production system that translates data into business impact.
What is Enterprise Grade Machine Learning?
Enterprise grade ML, a term mentioned in a paper put forth by Microsoft, refers to ML applications where there is a high level of scrutiny for data handling, model fairness, user privacy, and debuggability. While toy problems that data scientists solve on laptops using a csv dataset could be intellectually challenging, they are not enterprise grade machine learning problems.
The current state of Enterprise Grade ML
In many of our projects, the most difficult portion is understanding the business problem and defining a mathematical version that can be solved with the data that is available. Sometimes this mathematical version is not what the business stakeholders imagined it to be - this version might only partially solve the original business problem due to data realities. Very often, the business problem is broken down into smaller subproblems. The output of these subproblems then feed into a thin layer of business logic/rules to arrive at a final model output.
Once the problem is clearly defined, and data is flowing properly into the modeling environment, building a model is rather straightforward. When model building becomes convoluted, it can be taken as an indicator of an incorrect problem formulation. There are various ways to approach model building (feature creation, model selection, experimentation) ranging from fully custom approaches to highly automated processes. We are partial to the old-school Python-leveraging-packages approach but can envision the usefulness of AutoML if a data scientist has strong intuition about the business problem and solid understanding of the dataset.
In deployment (via containers or spark applications, for example), governance becomes paramount, especially in regulated environments. Data lineage, data versioning, model versioning, model explainability, model monitoring are all front and center.
Today, we very often need to stitch together ad hoc tools to accomplish all the above. What does the future look like? A recent paper outlines a 10-year prediction for enterprise-grade ML. Along the lines of Software 2.0, the authors view ML models as software derived from data. Most of us in the ML space would agree with this view, and would also acknowledge that even though ML is software, in today’s practice we don’t yet (always) adopt known best practices in software development.
Future state for Enterprise-Grade ML
The authors look to the future from three perspectives: i) model development/training ii) model scoring and iii) model management/governance.
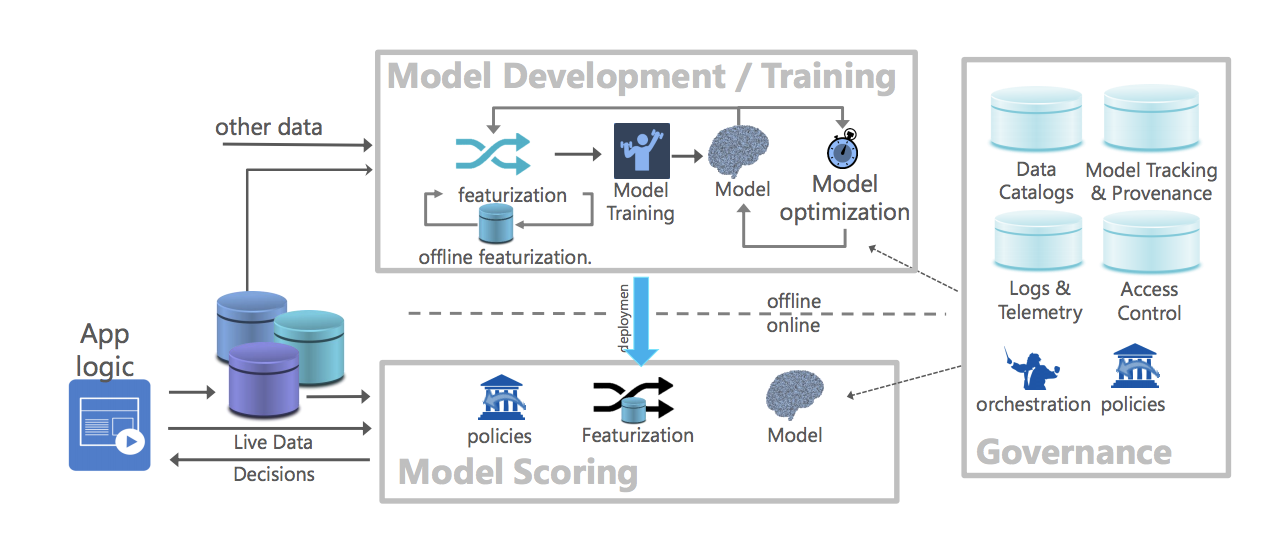
Reference architecture for canonical data science lifecycle (Flock). Image Source: https://arxiv.org/abs/1909.00084
On model development/training, they believe training and development work will move to the cloud, either private or public. This is consistent with our observations.
On governance, the authors believe that all data, including deployed models (to be thought of as derived data) and inferences made using them will need to be robustly governed. This is something we attempt to do in our current projects - capture code that trained the model, training data that went into it, model inference results - albeit in an ad hoc/brittle way, depending on existing architecture.
The most interesting viewpoint (to me) is their perspective on model scoring. Because machine learning models are software artifacts derived from data, the dual nature of software artifacts and derived data suggests that the boundary between the data world and the modeling world will be fuzzy. The authors believe that inference pipelines will be close to data, and inference on data stored in a database management system should be done as an extension of the query runtime. In other words, models should be represented as first-class data types in a database management system. To investigate this, they “integrated ONNX Runtime (a performance-focused inference engine for ONNX) within SQL server and developed an in-database cross-optimizer between SQL and ML to enable optimizations across hybrid relational and ML expressions.” Early results indicate that in-database management system inference is very promising.
As ML adoption quickens within enterprises and ML drives many business decisions, the attention will shift to effects of these models. To reach a state where ML models are defensible (privacy, security, interpretability, speed) without much technical debt, the DB community and the ML community will both shape the future of these ML end-to-end pipelines.









