Sep 24, 2015 · post
How do neural networks learn?
Neural networks are generating a lot of excitement, as they are quickly proving to be a promising and practical form of machine intelligence. At Fast Forward Labs, we just finished a project researching and building systems that use neural networks for image analysis, as shown in our toy application Pictograph. Our companion deep learning report explains this technology in depth and explores applications and opportunities across industries.
As we built Pictograph, we came to appreciate just how challenging it is to understand how neural networks work. Even research teams at large companies like Google and Facebook are struggling to understand how neural network layers interact and how the algorithms “learn,” or improve their performance on a task over time. You can learn more about this on their research blog and explanatory videos.
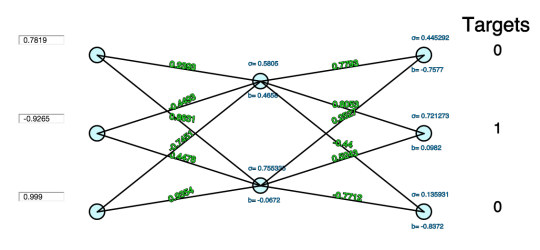
To help understand how neural networks learn, I built a visualization of a network at the neuron level, including animations that show how it learns. If you’re familiar with neural networks or want to follow the rest of the post with a visual cue, please see the interactive visualization here.
Neural Network Basics
First, some deep learning basics. Neural networks are composed of layers of computational units (neurons), with connections among the neurons in different layers. These networks transform data – like the pixels in an image or the words in a document – until they can classify it as an output, such as naming an object in an image or tagging unstructured text data.
Each neuron in a network transforms data using a series of computations: a neuron multiplies an initial value by some weight, sums results with other values coming into the same neuron, adjusts the resulting number by the neuron’s bias, and then normalizes the output with an activation function. The bias is a neuron-specific number that adjusts the neuron’s value once all the connections are processed, and the activation function ensures values that are passed on lie within a tunable, expected range. This process is repeated until the final output layer can provide scores or predictions related to the classification task at hand, e.g., the likelihood that a dog is in an image.
Neural networks generally perform supervised learning tasks, building knowledge from data sets where the right answer is provided in advance. The networks then learn by tuning themselves to find the right answer on their own, increasing the accuracy of their predictions.
To do this, the network compares initial outputs with a provided correct answer, or target. A technique called a cost function is used to modify initial outputs based on the degree to which they differed from the target values. Finally, cost function results are then pushed back across all neurons and connections to adjust the biases and weights.
This push-back method is called backpropagation - and it is the key to how a neural network learns a particular task.
Details of the Visualization
Play with the visualization to see how these components work. Notice how you can adjust the inputs. Each connection has the value of its weight hovering nearby; each neuron has its bias (b) below and the result of its activation function (σ) above.
Click `forward` to compare the final layer’s guesses with the target values. Click `backprop` to watch the values adjust. Click `forward` again to see the output layer improve slightly in comparison to the targets.
This visualization is designed to be as simple as possible to highlight the fundamentals. It uses a softmax function to compute cost and a sigmoid function for activation. Other aspects of normal training, like regularization, dropout, and mini-batching, are ignored.
Interpreting Learning
One powerful idea this visualization communicates is that, even in this simple network, changes made to a single value do not tell us much about the behavior of the network. This is one reason why neural networks are hard to interpret: discrete points provide little to no insight into the overall dynamics, even though backpropagation technically can be reduced down to tweaking individual parameters.
For this reason, we must think about neural networks as complex systems that exhibit emergent behavior: it is the interactions among the neurons, rather than the neurons themselves, that enable the network to learn. In a prior post, we visualized this with the metaphor of a bee swarm. Conway’s Game of Life provides another illustration, where complicated structures emerge from turning cells in a grid on and off according to a few basic rules.
As thinkers dating back to John Stuart Mill have hypothesized that consciousness emerges from brain matter, we may be tempted to infer another reason why neural networks function like brains. But brains are much more plastic and flexible than artificial neural networks. Neural networks are trained to perform a specific singular task; humans learn by switching contexts and redefining tasks as they encounter new information.
Still, the brain metaphor can help conceptualize how neural networks learn. Like brains, neural networks accept and process new input (“feed information forward”), determine the correct response to new input (“evaluate a cost function”), and reflect on errors to improve future performance (“backpropagate”).
It’s still unclear what kind of intelligence will emerge from neural networks in the coming years, but it’s important we understand how learning actually works to refine our conceptions of what’s possible. Hopefully our visualization helps to explain what learning means in this context. Grasping new AI systems is a difficult task, but an important for one for education, public communication, and choices about how to engineer systems with realistic expectations.
–Mike
homepage: http://mwskirpan.com
visualization: http://mwskirpan.com/NN_viz
viz code:https://github.com/wannabeCitizen/NN_viz/tree/gh-pages









