Apr 6, 2016 · guest post
Where Do You Put Your Data Scientists?

This is a guest post by Daniel Tunkelang, a data scientist and engineering executive, to preview the keynote he’ll deliver at our April 28 Data Leadership Conference in New York City!
In 2012, Harvard Business Review proclaimed that “data scientist” was the sexiest job of the 21st century. That’s pretty amazing, considering that the job title was less than five years old at the time.
The Rapid Rise of Data Science
DJ Patil and Jeff Hammerbacher, then at LinkedIn and Facebook, coined the term in 2008 to capture the intersection of analytics, engineering, and product skills that was becoming critical to their companies.
Prescient as they were to recognize the importance of data scientists, they barely knew how to describe the role. Here’s an early job ad:
Be challenged at LinkedIn. We’re looking for superb analytical minds of all levels to expand our small team that will build some of the most innovative products at LinkedIn.
No specific technical skills are required (we’ll help you learn SQL, Python, and R). You should be extremely intelligent, have quantitative background, and be able to learn quickly and work independently. This is the perfect job for someone who’s really smart, driven, and extremely skilled at creatively solving problems. You’ll learn statistics, data mining, programming, and product design, but you’ve gotta start with what we can’t teach—intellectual sharpness and creativity.
What a difference a few years makes! Today, it seems that everyone wants data scientists. Beyond social networks and beyond Silicon Valley, there are now data scientists in retail, finance, healthcare, and even the White House (both the real one, and the fictitious one in House of Cards).
Wherever there’s data, there are people trying to science it.
Building The Data Scientist Pipeline
The surging demand for data scientists has made data science an attractive career choice for many. Software engineers, physicists, and business analysts are among the thousands of professionals transitioning into careers as data scientists. Capitalizing on the demand, data science bootcamp programs offer to transform students into data scientists in just a few months. Universities, online and offline, are also racing to set up certificates and degree programs in data science.
Defining a data scientist has been an ongoing debate, but most people accept some variant of Drew Conway’s “data science Venn diagram,” which places data science at the intersection of hacking, math / statistics, and domain knowledge.
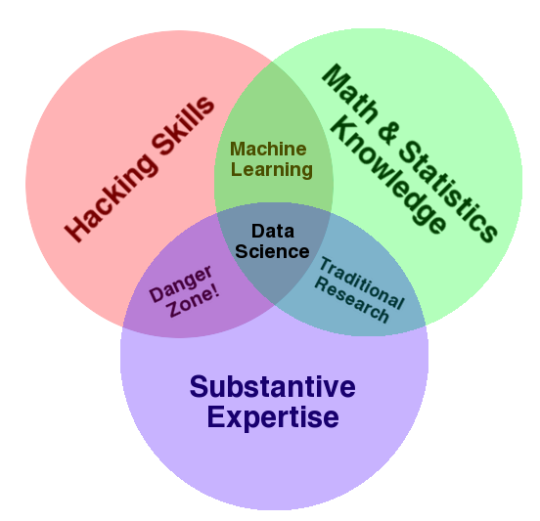
This diagram has been a useful guide for many data science managers, but it’s deliberately underspecified. In particular, you have to figure out your own thresholds for each of these skill sets. Do you need people who already have specific engineering skills (i.e., knowledge of Spark) or can you afford to have them learn on the job? As for math, clearly your data scientists need to understand basic probability and statistics, but do they need to understand tensors and martingales? And how much does prior domain knowledge really matter? Don’t make the mistake of chasing data scientists who excel at everything – you’ll be chasing unicorns, and even if you’re lucky enough to find them, you’ll struggle to retain them.
Where Do You Put Your Data Scientists?
Difficult as it is to hire data scientists, it’s only the first step. Once you find great data scientists, where do you put them in your organization to set them up for success?
As companies increasingly rely on data as a core asset, a data science team can deliver enormous value by enabling companies to build better products and make better decisions using that data. So it’s not surprising that many executives are convinced they need data scientists yesterday.
But those same executives often don’t know how to hire data scientists, where to put them, or what to do with them. Data science isn’t a pixie dust you can just scatter on your organization. And a data science team that isn’t set up for success is an expensive and counterproductive distraction.
There are three prevalent organizational models for data science:
- A stand-alone model, where data science acts an autonomous unit;
- An embedded model, where a head of data science brings in talented people and farms them out to the rest of the company; or
- An integrated model, where data scientists report directly into the teams that need them.
Each model comes with its own set of tradeoffs, and it’s important to understand those tradeoffs in order to pick the right model – or hybrid approach – to address your company’s particular needs.
Looking Forward to Fast Forward!
I’m excited to give the keynote at the Fast Forward Labs Data Leadership Conference on April 28 in New York City! In my talk, I’ll focus on the organizational challenges of establishing a data science team and dive into the tradeoffs of the models outlined above. I hope to see you there, and encourage you to bring questions about how to succeed with data science in your organization.
- Daniel Tunkelang









