Aug 7, 2017 · post
The Business Case for Machine Learning Interpretability
Last week we launched the latest prototype and report from our machine intelligence R&D team: Interpretability.
Our prototype shows how new ideas in interpretability research can be used to extract actionable insights from black-box machine learning models; our report describes breakthroughs in interpretability research and places them in a commercial, legal and ethical context. This research is relevant to anyone who designs systems using machine learning, from engineers and data scientists to business leaders and executives who are considering new product opportunities.
We will host a public webinar on interpretability on September 6 2017, where we’ll be joined by guests Patrick Hall (Senior Data Scientist at H2O, co-author of Ideas on Interpreting Machine Learning) and Sameer Singh (Assistant Professor of Computer Science at UC Irvine, co-creator of LIME, a model-agnostic tool for extracting explanations from black box machine learning models). There will be lots of opportunities for the audience to ask questions, so we hope you’ll join us!
In this post we’re going to look at the business case for interpretability. What advantages are there to building interpretable machine learning systems?
The Power of Interpretability
A model you can interpret is one you, regulators, and society can more easily trust to be safe and nondiscriminatory. A model whose decisions can be explained opens up the possibility of new kinds of intelligent products. An accurate model that is also interpretable can offer insights that can be used to change real-world outcomes for the better. And a model you can interpret and understand is one you can more easily improve. Let’s look at these in more detail.
Enhancing Trust
If we are to trust a machine learning model to perform accurately, and to be safe and non-discriminatory, it is important that we understand it.
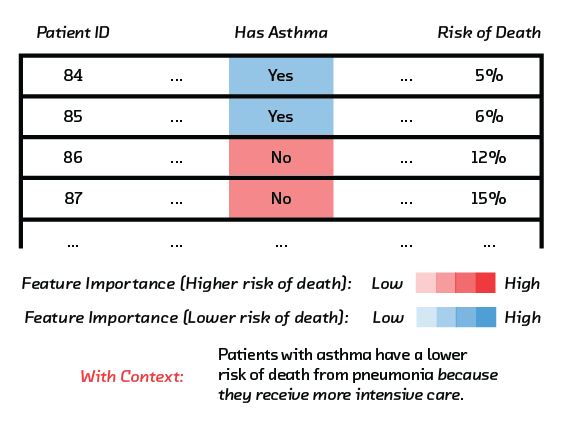
A paper by Rich Caruana and colleagues gives a powerful example of the danger of deploying a model you do not understand. They describe a model that recommended whether patients with pneumonia should be admitted to hospital or treated as outpatients. This model was interpretable, and it was immediately obvious by inspection that the model had acquired a lethal tendency to view pneumonia patients who also have asthma as low-risk. This was wrong, of course. Asthma patients with a pulmonary infection should be admitted to hospital. In fact they often are, and this was the problem. Such treatment makes their prognosis better, and this pattern was present in the historical training data.
This problem was only spotted because the model was interpretable. We discuss what makes a model interpretable in more detail in the report. Similar risks lurk in any model applied in the real world.
Satisfying Regulations
In many industries and jurisdictions, the application of algorithms is constrained by legal regulations. Even when it’s not, it should be constrained by ethical concerns.

It is extremely difficult to satisfy regulations or ethical concerns if the model is uninterpretable. For example, the US Fair Credit Reporting Act requires that agencies disclose “all of the key factors that adversely affected the credit score of the consumer in the model used, the total number of which shall not exceed 4.” It’s difficult to satisfy this regulation if your credit model is a deep neural network. Difficult, but as we show in the report, thanks to new research, not impossible!
Explaining Decisions
Some kinds of interpretability allow you to offer automated explanations for individual decisions. A model that makes a prediction is useful, but a model that tells you why the prediction was made is even more powerful. Our prototype product, Refractor, demonstrates this. It offers explanations for the reasons customers are predicted to leave a subscription business. This allows the user to identify both global weaknesses in the product, and individual complaints. Most excitingly, it raises the possibility of intervening to change outcomes.

Refractor is built on top of LIME, a model-agnostic tool that can be applied to a trained black-box model, so data scientists don’t need to change the way they build their models to apply this technique. Our report describes our application in conceptual and technical terms, and looks closely at how it could be deployed in a business.
Improving the Model
Finally, interpretability makes for models that simply work better. Debugging an uninterpretable, black-box model is time consuming, and relies at least in part on trial-and-error. Debugging an interpretable model, however, is easier because glaring problems stand out. Having insight into the attributes that are likely causing trouble can motivate a theory about how the model works, which saves time when tracking down problems.
Conclusion
The future is algorithmic. White-box models and techniques for making black-box models interpretable offer a safer, more productive, and ultimately more collaborative relationship between humans and intelligent machines. We are just at the beginning of the conversation about interpretability and will see the impact over the coming years.









