Sep 1, 2017 · post
Crowdwork for Machine Learning: An Autoethnography
Amazon’s Mechanical Turk is a platform for soliciting work on online tasks that has been used by market researchers, translators, and data scientists to complete surveys, perform work that cannot be easily automated, and create human-labeled data for supervised learning systems. Its namesake, the original Mechanical Turk, was an 18th-century chess-playing automaton gifted to the Austrian Empress Maria Theresa. An elaborate hoax, it concealed a human player amidst the clockwork machinery that appeared to direct each move on the board. Amazon’s Mechanical Turk (mTurk), which they call “artificial artificial intelligence,” isn’t all that different. From the outside, mTurk appears to perform tasks automatically that only humans can, like identifying objects in photographs, discerning the sentiment towards a brand in a tweet, or generating natural language in response to a prompt. Behind the scenes, however, there are actual human beings - crowdworkers - logging in and performing each of these “human intelligence tasks” (HITs), usually for a few pennies per task.
Amazon’s artificial artificial intelligence has proven useful for ‘real’ AI applications as a source of labeled data for training supervised machine learning algorithms. Supervised machine learning fits squarely under the umbrella of AI, and mTurk’s role in supervised learning is crucial for understanding the development of AI. Because of the role crowdwork plays as a source of the human knowledge that machine intelligence relies on to train algorithms, a better understanding how crowdworking platforms like mTurk function as a conduit for human intelligence can improve its usefulness for the data scientists that rely on it.

I engaged in an autoethnographic exercise, working as an mTurker to “systematically analyze” the world of crowdworkers. Using myself as both instrument and unit of analysis, I spent a day working on the mTurk platform (I also tried out Crowdflower), navigating the idiosyncrasies of the platform and trying to optimize my earnings against the time I spent performing tasks. I asked: How does crowdwork affect data science products? And what do data scientists need to know about crowdworking that would help them design tasks that support better machine learning?
There is very compelling ethnographic research on crowdwork that has challenged the assumption that crowdworkers are individuals working independently on tasks; the research shows that the crowdworking community has developed a sociality of its own, with elaborate practices for sharing information about particular tasks and strategies for maximizing earning and minimizing drudgery. Rather than exploring that side of the crowdworking experience, I tried to focus my attention on tasks that looked like they were intended to support machine learning (rather than the various other services that mTurk supports, like psychological profiles, market research surveys, or translation tasks), and found that the design of mTurk HITs have important consequences for data scientists concerned with producing useful labeled data.
Labeled data, of course, is necessary for training any supervised machine learning algorithm. Correctly labeled data points have inputs (handwritten characters, images, spoken words, or elements of an array) that match their outputs (the particular character, object, word, or entity). The algorithm learns the complex mathematical relationship between these inputs and their outputs from a large training set of labeled data and then tests its own accuracy against a smaller test set of labeled data. Pre-labeled data sets occasionally can be found out in the wilds of the internet, as well-curated structured data or standard training sets like MNIST or ImageNet, or can be engineered by inferring labels from proxies (by using product categories from eBay as the labels for item listings, for example). But sometimes data needs new labels, and because the algorithm the data will train should function to classify objects just as a human would, it takes a human to label the training (and testing) data. This is where crowdworkers come in.
Artificial Artificial Intelligence
Taking the expectation that mTurk workers should produce results that look as though they were generated by an artificial intelligence too literally has led to unrealistic expectations for consistency on the part of HIT designers [read: data scientists]. This has produced a HIT ecosystem that is (…sorry…) more artificial than it is intelligent. What I learned by joining the ranks of mTurkers (if only for a short time) was that the structure of the mTurk platform optimizes for workers who are good at performing the kinds of tasks that are offered on the platform.
Take, for example, the mismatch between instructions for tasks, training examples, and the tasks themselves. If the goal of a task is to provide labeled data on which to train a machine learning model, then consistency in the labels is very important, but the emphasis on consistency should be balanced by a broader concern with capturing human knowledge. This comes across in the instructions given to the crowdworker, as they are highly specific and attempt to cover all possible variations of the task a crowdworker is likely to encounter. These instructions are buttressed by a training and evaluation stage that a crowdworker must pass successfully to reach the work stage.
These training tasks, which the worker must complete above a certain threshold error rate, were not (in my experience) very well-matched with the instructions, or with the subsequent ‘real’ tasks. Because of this, I found it very difficult to actually qualify for working on ‘real’ tasks. I spent two hours trying to pass the evaluation questions for one task, but what seemed (to me) like perfectly valid answers were consistently rejected, without explanation. For other tasks, I was given the opportunity to offer criticism of the training questions, and upvote possible reasons as to why the question was inaccurate or unfair.
While this training round for embedding human intelligence in machine learning products ensures some degree of consistency and limits error to an acceptable rate, it also filters out many reasonable responses - responses likely to be generated in the real world to similar prompts that are not captured by the validation rules for the task. The human intelligence appended to the dataset through the crowdwork platform comes to resemble the validation rules more than it does the range of likely responses.
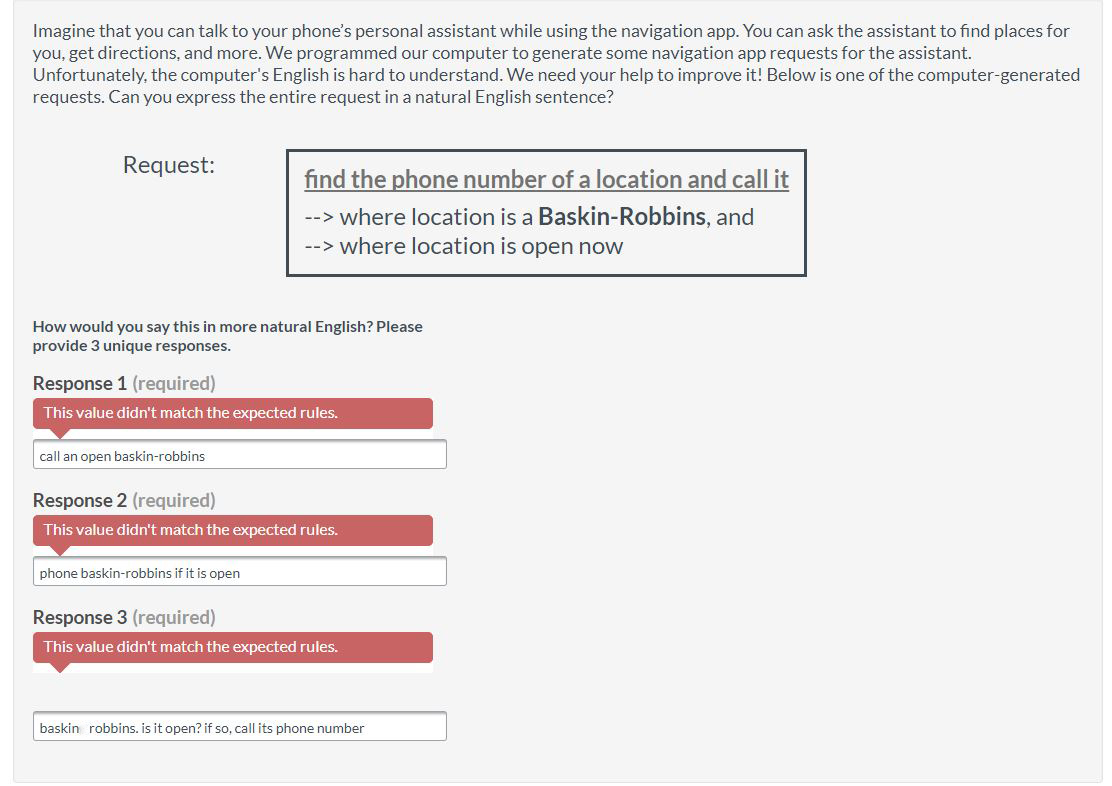
The task platform itself is also a barrier to capturing the range of human intelligence that might otherwise be possible. No matter how extensible the task-building platform is, there are only a few ways for task designers to elicit information from task workers: Writing text in fields, selecting radio buttons or checkboxes, or using dropdown menus are the most database-friendly methods, but recording audio, capturing video or still photos from a webcam, or asking for drawn annotations may also be used. In my time as an mTurker, I drew boxes around food items in pictures, populated fields in a form based on my interpretation of the description of a product listing on a shopping site, read short snippets of text and clicked radio buttons associated with true or false statements about the text, and suggested multiple versions of passably natural language for very specific voice commands (< search > for < phone number > and < location > and < perform action >).
Here, the purpose and promise of crowdwork for supporting machine learning collapses somewhat, in that the platform is supposed to offer an automated mechanism for human discernment to be applied to data. In practice, however, human discernment is restricted in a few ways: through selection bias, through reliance on overly mechanical interfaces, and through cultural biases. Those performing the majority of the tasks are those who have qualified for a high ranking on the platform itself by performing a large number of tasks with an acceptable level of error. What this means is that their responses on tasks are highly calibrated to the validation rules for the tasks themselves.
The effect of this is that those who complete the most tasks are good at meeting validation rules, but not necessarily good at performing the human intelligence task that is at issue. They might not be particularly skilled at identifying objects in photos, but are instead quite good at drawing boxes. They might not be particularly skilled at generating natural language, but instead at discerning the validation rule that allows their responses to be accepted.
Crowdwork, I suggest, is susceptible to “teaching to the test” - the results it produces are not accurate representations of the world the task creator is interested in, but instead are accurate reflections of the validation rules the task creator puts in place to standardize the crowdwork itself. While this might produce highly consistent data (no doubt it does), using this highly consistent data to train a machine learning model encodes not so much real-world human knowledge, but the validation rules that the data scientist already had before gathering the data through crowdwork.
Psychological and Cultural Factors
A key component of any ethnographic exercise, even an autoethnographic exercise like the one I engaged in, is to reflect on one’s own position as a researcher and how that position is inflected by the many social connections between a researcher and their object of study. As a U.S. citizen and New York City resident with a graduate education, I hold a perspective different from that of many other crowdworkers. This difference is an important framing for my own understanding of how crowdwork happens, but is also crucial for considering how human intelligence is applied to completing crowdwork tasks.
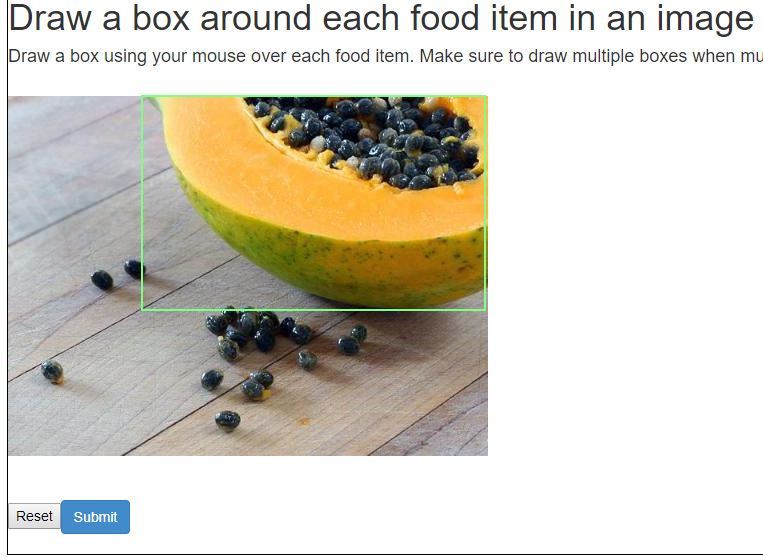
In general, lower-priced tasks are more likely to be completed by non-US workers. This isn’t a problem per se, but it should be recognized that when tasks are intended to embed human knowledge into a data set, and then used to train a machine learning model, the human knowledge is inseparable from the cultural knowledge that frames it. It goes without saying that I can recognize what parts of an image contain food items and which do not, but when asked to draw a bounding box around the “food” part of the image, I had some level of difficulty. Do I include the bowl that the soup is in? I cropped it out. Are papaya seeds edible? Should I draw a box around them? Do I include the paper wrapper around a burrito, or just the part that was visible? Or just the part with the bite taken out, where I could see the delicious contents? I cropped out the paper, but cropped in the tortilla. Is this what the creator of the task would have wanted? How did my own (copious) experience with burritos affect how I completed this particular task item?
The pace with which work gets done is also subject to some of these factors. When designing a project expecting workers from all around the world to contribute to it, various economies come into play. The more the project pays, the faster it will get done. But as you lower the price for a task, not only does the turnaround time rise, but the spread of workers contributing to the project changes as well. Lower-priced tasks are less likely to be taken by US workers in locales with high costs of living, and are less likely to be taken up by experienced workers, overall.
Designing Better Tasks
What can be done about the “teaching to the test” problem?
There is extensive existing literature on designing crowdwork tasks that offers many creative ways of validating tasks. By inserting ‘gold’ tasks that you already know the answer for, you can filter out all work from those who don’t get those known tasks correct. Or, by soliciting multiple responses to identical tasks, you can filter out anomalous responses, keeping only the types of responses on which there is substantial agreement. These methods still fall victim to the “teaching to the test” problem, however. They also require the reduplication of effort: paying twice (or more) for a single task, or throwing out work that didn’t get the ‘gold’ questions right.
I suggest, then, that task designers could leverage the “human” aspect of the “human intelligence tasks.” By loosening validation rules and soliciting a broader range of responses, it is possible to get a more realistic representation of the data from the tasks created, even if it does leave more room for “incorrect” responses. Rather than rejecting “wrong” answers, or averaging across multiple responses, instead these responses can be passed on as a second type of task, to a second group of crowdworkers. In this second pass, crowdworkers can evaluate whether or not the response is suitable or not, or can (potentially) correct the original response.
For example, consider an image labeling task: the first task would solicit labels for images, and then the second task would supply the image with the labels and ask whether the labels were “good” labels or not. This kind of double validation is a fairly straightforward way to avoid “teaching to the test” and would, I believe, avoid overly deterministic labels for training data. Other methods might also be effective, or might even be in common practice, although I couldn’t find many in my literature review.
Conclusion
I know that my experience barely scraped the surface of the kinds of tasks that are available on crowdworking platforms. I also only waded into the shallow end of the online forums that crowdworkers generally use to discuss rewarding tasks, complain about unfair or inconvenient labor practices on these sites, and strategies for maximizing their work. Having seen both sides of the crowdworking coin, however, I would strongly recommend that task requesters visit these forums regularly, to get a sense of who their most dedicated workers are, how they approach their work, and how their work habits affect data.
Do you regularly use mTurk? Crowdflower? Have you tried out Stanford University’s worker-first platform Daemo? What other platforms are commonly used? What experiences have you had with them? What should others know about using crowdwork for training models?
Designing Crowdwork Tasks References:
- Khattak, Faiza Khan. 2016. “Toward a Robust Crowd - Labeling Framework Using Expert Evaluation and Pairwise Comparison Ansaf Salleb - Aouissi.” Journal of Artificial Intelligence Research 1 (16): 1–15.
- Posch, Lisa, Arnim Bleier, and Markus Strohmaier. 2017. “Measuring Motivations of Crowdworkers: The Multidimensional Crowdworker Motivation Scale.” http://arxiv.org/abs/1702.01661.
- Whiting, Mark E, Dilrukshi Gamage, Snehalkumar (Neil) S Gaikwad, Aaron Gilbee, Shirish Goyal, Alipta Ballav, Dinesh Majeti, et al. 2017. “Crowd Guilds: Worker-Led Reputation and Feedback on Crowdsourcing Platforms.” Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing, 1902–13. doi:10.1145/2998181.2998234.
- Mankar, Akash, Riddhi J. Shah, and Matthew Lease. 2016. “Design Activism for Minimum Wage Crowd Work.”
- Dang, Brandon, Miles Hutson, and Matt Lease. 2016. “MmmTurkey: A Crowdsourcing Framework for Deploying Tasks and Recording Worker Behavior on Amazon Mechanical Turk,” no. Figure 1: 1–3. http://arxiv.org/abs/1609.00945.
- Staffelbach, Matthew, Peter Sempolinski, David Hachen, Ahsan Kareem, Tracy Kijewski-Correa, Douglas Thain, Daniel Wei, and Gregory Madey. 2014. “Lessons Learned from an Experiment in Crowdsourcing Complex Citizen Engineering Tasks with Amazon Mechanical Turk.” Collective Intelligence Handbook.
- Chen, Di, Kathryn T. Stolee, and Tim Menzies. 2017. “Replicating and Scaling up Qualitative Analysis Using Crowdsourcing: A Github-Based Case Study.” http://arxiv.org/abs/1702.08571.









