Sep 28, 2018 · newsletter
Realistic Video Generation
Generative Adversarial Networks (GANs) wowed the world in 2014 with their ability to generate what we considered to be realistic images. While these images were quite low resolution, researchers kept working on how to perfect these methods in order to increase the quality of the images and even to apply the algorithm on other types of data like text and sound.

However, until recently there has been little success in making realistic videos. The main problem with making videos is temporal consistency: while people can be forgiving in one frame and find some interpretation for unrealistic regions, we are adept at seeing inconsistencies with how videos progress.

For example, we can accept some strange looking texture in the background of an image as simply some strange looking background. However, if that background is randomly changing from frame to frame in a video, we immediately discount the video. It is exactly this temporal consistency which has plagued researchers trying to apply GANs to videos – while each frame seemed realistic taken on its own, when assembled into a video, there were considerable inconsistencies which ruined any illusion of realism. This restricted the ability to reuse models that showed success at generating individual images, and forced researchers to come up with new methods to deal with the temporal nature of videos.
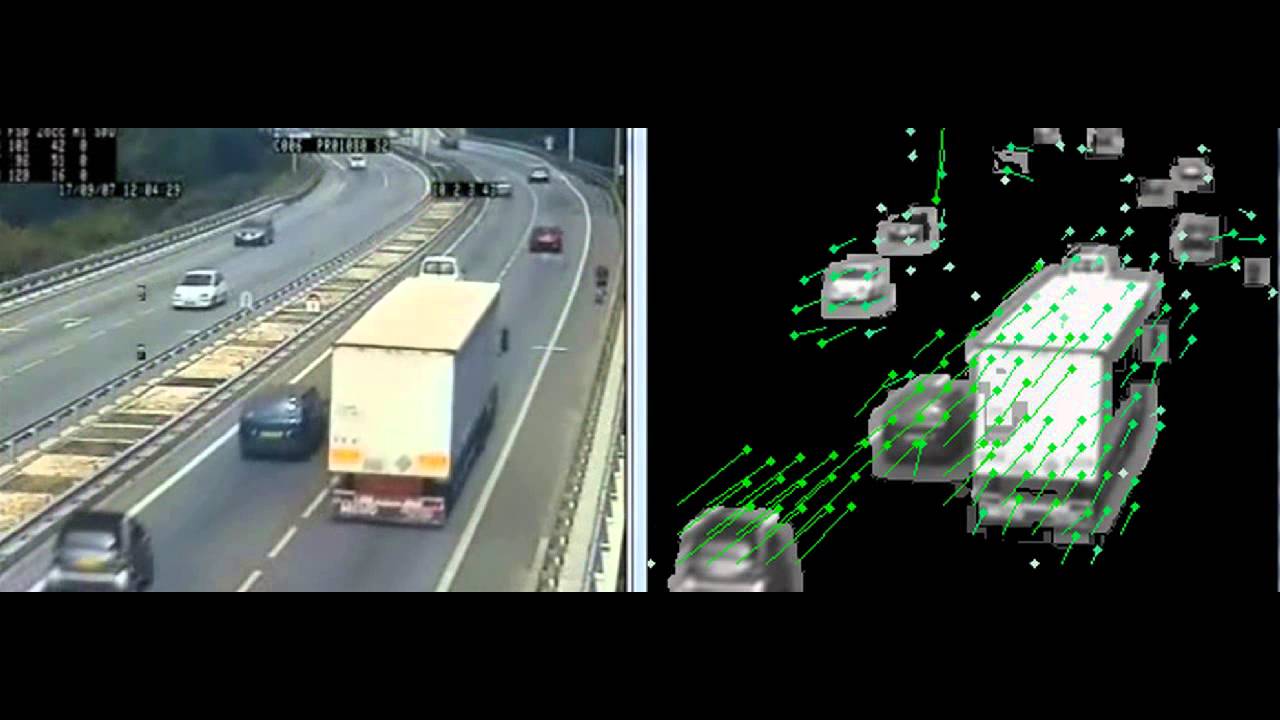
Recently, researchers at NVIDIA and MIT have come up with a new type of GAN, vid2vid, which primarily addresses this problem by explicitly incorporating how things seem to be moving within the video, in order to continue this motion in future frames. (In addition, they follow previous work, which uses a multi-resolution approach for generating high resolution images). This is done by calculating the optical flow of the image, which is a classic computer vision method that simply has not been incorporated into such a model until now.

The results are quite staggering (we highly recommend watching their release video). With the model you can create dashboard camera footage from the initial segmentation frame (allowing you to change the type and shape of objects in the frame by simply drawing in the corresponding color); it’s even possible to create realistic looking dance videos from pose information. It’s interesting to see this new method as compared with previous methods, to really get a sense of how important this additional temporal information is for making realistic results.

These high quality results are quite exciting and are groundbreaking work in the field of video generation. From applications in generating synthetic training data to use in creative projects, the vid2vid model itself is instantly applicable.
Even more interesting is how the field as a whole will learn from this research and start finding ways to incorporate other classic algorithms into neural networks. Just as conv-nets explicitly encoded the two dimensional understanding we have for images into models so that they can more quickly and accurately learn how to work with that data, this method explicitly encodes our understanding of how frames of a video flow from one to another (albeit this was much trickier to do than the conv-net example!). We’re interested in seeing what other algorithms will be incorporated into neural networks like this and what capabilities these models will have.









