Aug 28, 2019 · newsletter
NLP and Transfer Learning
NLP and Transfer Learning
Natural language processing just took a leap forward with the release of new high-quality language models combined with transfer learning. As you know, at Cloudera Fast Forward Labs, we have been researching this leap forward and have just finished a new report on the topic.
These new NLP models rely on deep neural networks, which are data hungry and compute intensive to train. Various research groups trained these new models with tremendous amounts of data and compute power. They are also aware of the sequential nature of language, i.e., the flow of words and sentences, and the context in which words appear. These models have a much more nuanced understanding of language than prior approches, and they’re now available for anyone to use:
- BERT (Google)
- ELMo (AllenNLP / UW Computer Science and Engineering)
- ULMFiT (available through fast.ai libraries)
- GPT-2 (OpenAI)
These models are very powerful, but they are limited, at least facially, to the task for which they were trained. Specifically, they are trained to generate language, i.e., predict the next words following an input prompt. Training a model for this task is straightforward because any text is self-labeling - that is: any text can be used as input data because the next word is always known, so the model can guess the next word and then check the next word to see whether it was correct.
Training models for other tasks requires data that is harder to obtain. For example, sentiment analysis - the task of predicting how an author feels based on their writing - would require writing samples labeled with the author’s actual opinion. Labeling this data requires a human to read the text and make their own assessment of the author’s feeling about the subject (positive, negative, or neutral). This training data is very expensive to create.
The technique of transfer learning adapts recently-released pre-trained language models for other tasks. Transfer learning uses the pre-trained models’ extensive understanding of language and applies it to new tasks with relatively little training data. So a pre-trained model can be adapted to the task of sentiment analysis with very little labeled sentiment data.
The chart below shows the accuracy of several models predicting sentiment as a function of how many labeled training examples each model was shown. For example, a naive Bayes support vector machine and a word vector model (both older technologies) scored around 50% accuracy – about the same as guessing – when shown 100 training examples. Two of the newer pre-trained models, BERT and ULMFiT, adapted for sentiment analysis, are 85% accurate with the same 100 training examples.
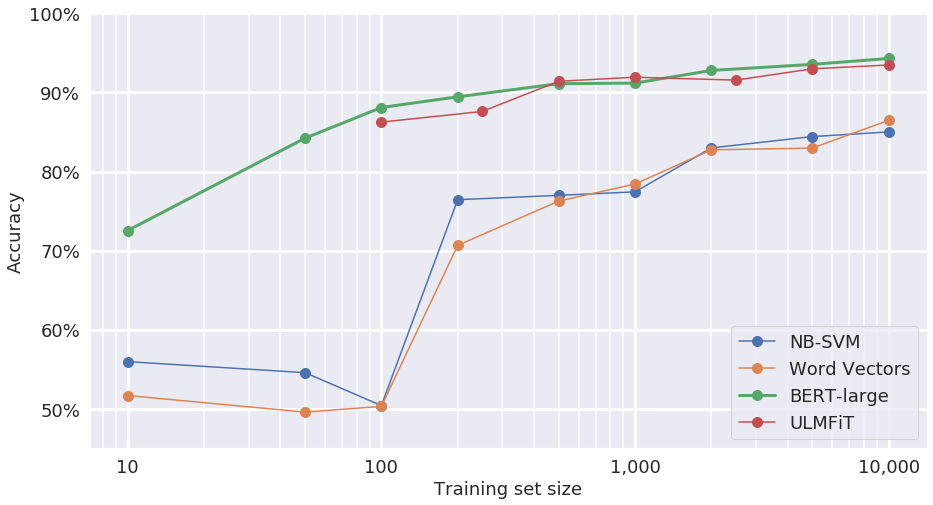
Not only do the pre-trained models work with fewer labeled examples, they also work better than the older technologies at any number of labeled examples.
These models permit higher performance with less data, and they are easier to use than traditional deep learning models, so they don’t require a data scientist with NLP specialization. They can also be adapted to any natural language task. Here are some examples of these tasks:
- Customer service - routing customer phone calls or emails based on what the customer says they want
- Marketing - understanding public opinions about a new product or service
- Document management - understanding what information a document contains
- Search - looking for answers to questions within text data
So with pre-trained models and transfer learning, many NLP tasks are now accessible without a great deal of labeled data, without an NLP PhD on staff, and without special computer hardware. This opens up dozens of possibilities.









